1. Why CNN?
In earlier dates, we used a fully connected (dense) multilayer perceptron (MLP) network to classify handwritten digits. (You can go to this link to have a closer look into how we do that with the MNIST dataset). However, there are several drawbacks:
-
MLP cannot understand the 2D spatial meaning of the image. What it does is simply looking at each pixel of the image, which is inefficient.

MLP misinterpreted the image - learnopencv.com
-
If we keep doing that, the number of nodes or neurons scales linearly to the number of pixels in the image. As images get larger and larger, training these models becomes a burden.
Fortunately, CNN architecture comes in and solves these issues elegantly. In essence, this type of architecture contains an upstream feature extractor followed by a downstream classifier.
2. CNN in details
A CNN model contains many components, which we are diving into right now!
2.1 Convolutional Blocks & Convolutional Layers
Convolutional Block consists of several Convolution Layers. A convolutional layer can be considered as the “eyes” of the model.
- Input: an array of numbers
- Output: another array of numbers
Behind the scenes, there is a filter which is referred to as kernel, which is an n x n array of numbers, being slid through the input. At each location, the convolutional operation is performed, which is another fancy name for calculating the dot product. Hence the name “Convolutional Neuron Network”!
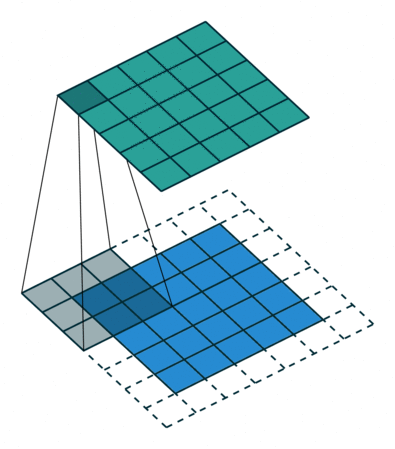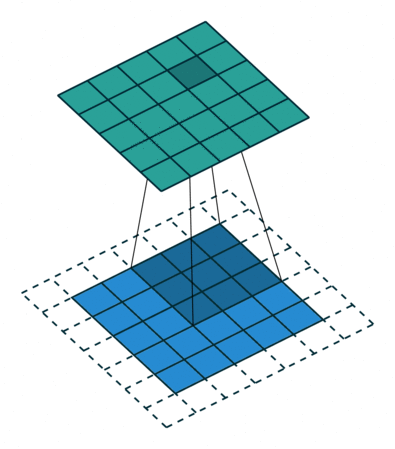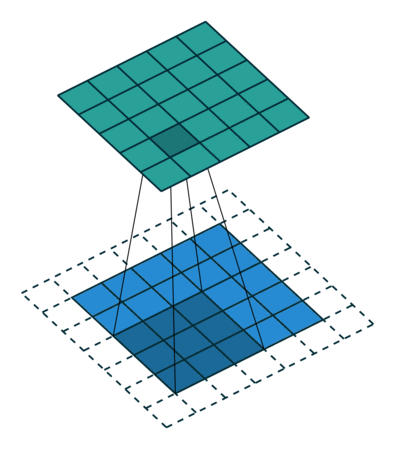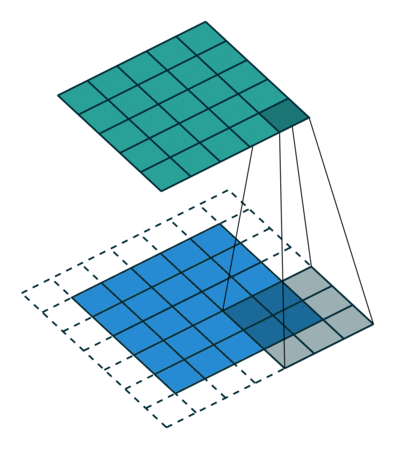
Filter being slid through the input - deeplizard.com
In the above example, a 3x3 filter is being slid through a 5x5 array (blue), giving a 5x5 array (green) as output. The white, dotted part is where we perform padding, which will be discussed later.

Convolution Operation - learnopencv.com
Some terminology:
- Receptive field: the area covered by the kernel